This is an Eval Central archive copy, find the original at freshspectrum.com.
Today’s post is a little evaluation graphic novella inspired by Schrödinger’s cat. No cats, real or fictional, were harmed while creating this post. I’ll drop a plain text version at the bottom.














Plain Text Version
Schrodinger’s Outcome
Imagine a nonprofit program. Let’s say a food pantry.
The food pantry was created to provide free emergency food assistance to residents within a specific city or town.
It receives funding in the form of donations and grants. It also draws volunteers from the surrounding area.
Is it successful?
Maybe yes, maybe no.
Maybe yes and no.
There is a point to which every activity and program exists as both wildly successful and a total failure.
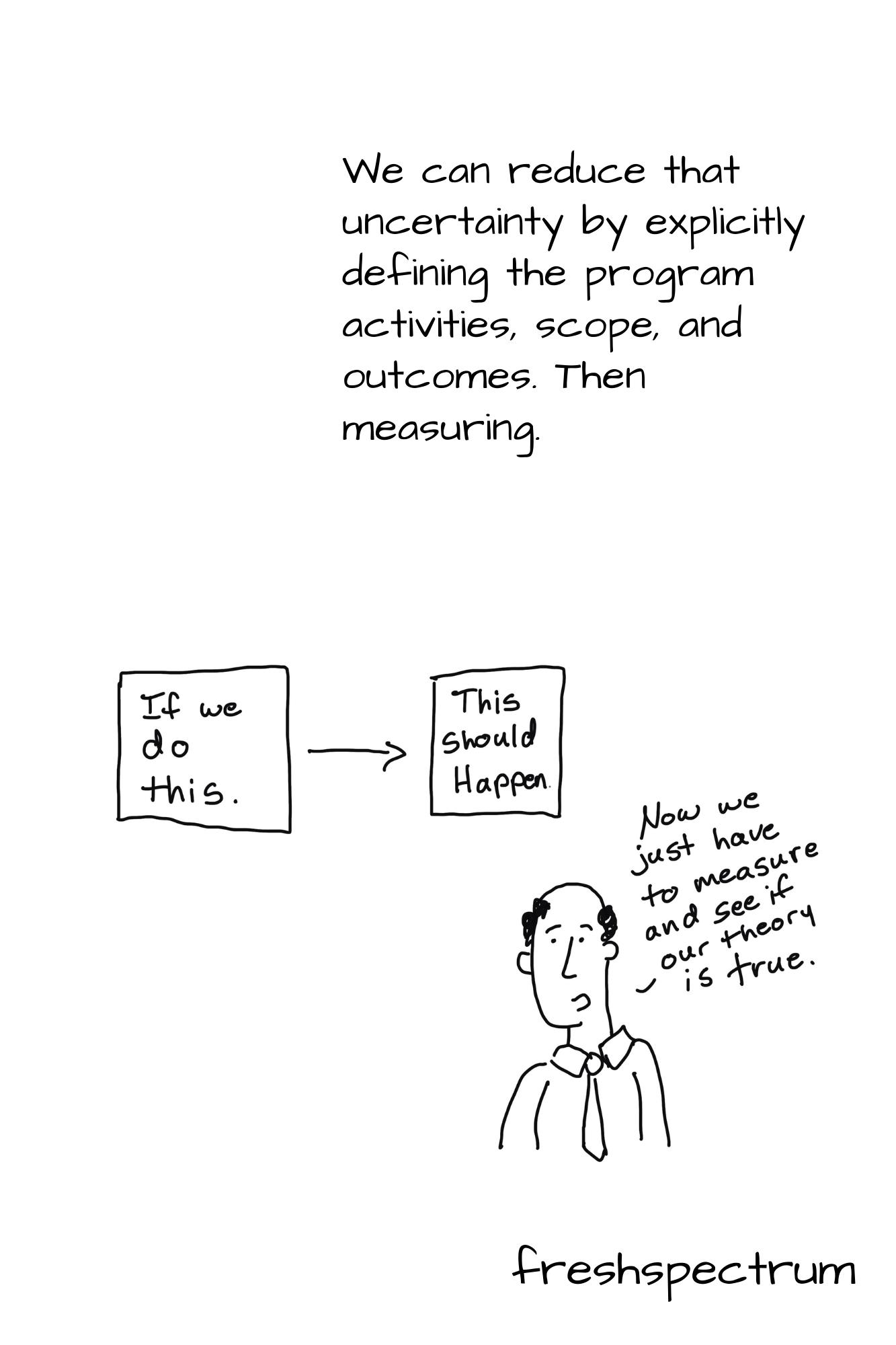
We can reduce that uncertainty by explicitly defining the program activities, scope, and outcomes. Then measuring.
But if you already see the program as wildly successful, why measure?
Would you believe it if an evaluator showed you evidence that the program wasn’t a success?
And if you already see the program as a total failure, why measure?
Would you believe it if an evaluator showed you evidence that the program wasn’t a failure?
The biggest challenge in evaluation isn’t defining, measuring, collecting, or interpreting evidence.
The biggest challenge is defining, measuring, collecting, and interpreting evidence while developing enough stakeholder trust in your process and your team that your analysis will actually be heard and believed.
Evaluation is not just answering questions.
But confirming or rejecting the things we think we do know.
And then sharing that information so that others will see what we see.